
회귀분석
독립변수 : 입력이나 원인을 나타내는 변수 , x
종속변수 : 결과물이나 효과를 나타내는 변수, y (+)일반 선형회귀는 종속변수가 연속형 변수일 때 가능하다.
잔차(오차항) : 계산에 의해 얻어진 이론값과 측정값의 차이
오차(Error) > 모집단, 잔차(Residual) > 표본집단
회귀분석이란?
하나 또는 그 이상의 독립변수들이 종속변수에 미치는 영향을 추정할 수 있는 통계기법
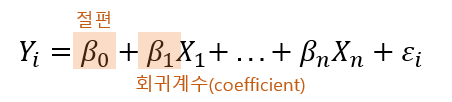

최소제곱법(Least Square Method)
잔차를 제곱한 것의 합이 최소가 되도록 하는 절편과 회귀계수를 구하는 방법
회귀 모형의 가정
| 선형성 | 독립변수의 변화에 따라 종속변수도 변화하는 선형 모형이다. | |
| 독립성 | 잔차와 독립변수의 값이 관련되어 있지 않다 (Durbin-Watson 통계량 확인) | |
| 정규성(정상성) | 잔차항이 정규분포를 이뤄야한다. | Normal Q-Q plot |
| 등분산성 | 잔차항들의 분포는 동일한 분산을 갖는다. | Scale-Location |
| 비상관성 | 잔차들끼리 상관이 없어야 한다. |
Cook's Distance : 일반적으로 1값이 넘어가면 관측치를 영향점으로 판별

회귀모형의 검정
| 확인 요소 | 확인 방법 | 구하는 법 |
| 모형이 통계적으로 유의미한가? (통계적 유의성) |
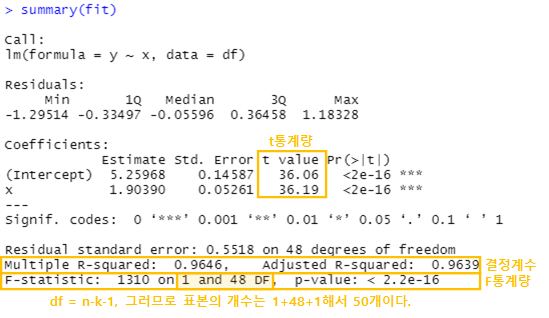
F 통계량, 유의확률(p-value)로 확인 | F 통계량 = 회귀제곱평균(MSR)/잔차제곱평균(MSE) 당연히 F통계량을 클수록 유의하며, p-value는 보통 0.05보다 작을때 유의하다고 한다. |
| 회귀계수들이 유의미한가? | 회귀계수의 t값, 유의확률(p-value)로 확인 | t 값 = Estimate(회귀계수)/std.Error(표준오차) 당연히 F통계량을 클수록 유의하며, p-value는 보통 0.05보다 작을때 유의하다고 한다. |
| 모형이 얼마나 설명력을 갖는가? (회귀식 적합도) |
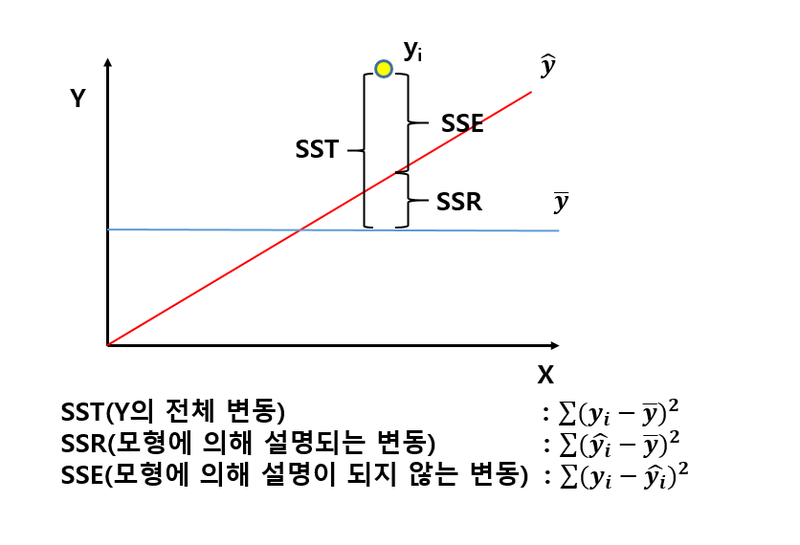
결정계수(R^2)확인 0~1사이의 범위를 가지며 전체 분산중 모델에 의해 설명되는 분산의 양을 뜻함. |
결정계수 = 회귀제곱합(SSR)/총제곱합(SST) = 1-(SSE/SST) 결정계수가 커질수록 설명력이 높아짐 (아래 그림 참고) |
| 모형이 데이터를 잘 적합하고 있는가? | 잔차 통계량 확인, 회귀진단 선행(선형성~정상성) |
다중공선성(Multicollinearity)
모형의 일부 설명변수(=독립변수)가 다른 설명변수와 상관되어 있을 때 발생하는 조건(선형관계가 존재)
중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 됨
R에서 vif함수를 이용해 구할 수 있으며 VIF(variance inflation factor 분산팽창요인)값이 10이 넘으면 다중공선성이 존재한다고 본다.
해결법? 높은 상관 관계가 있는 설명변수를 모형에서 제거
그러면 대부분의 R-square가 감소한다. 그래서 단계적 회귀분석을 사용해 제거
변수선택법
| 모든 가능한 조합 | 모든 가능한 독립변수들의 조합에 대한 회귀모형을 분석해 가장 적합한 모형 선택 | |
| 후진제거법 | 독립변수 후보 모두를 포함한 모형에서 출발해 하나씩 제거 | step(lm(~~~),direction='backward') |
| 전진제거법 | 절편만 있는 모델에서 출발해 변수를 차례로 추가 | step(lm(~~~),direction='forward') |
| 단계별방법 | 전진선택법에서 출발해 변수를 추가하다가 새롭게 추가된 변수에 기인해 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가, 삭제 되는 변수를 검토하는 방법 | step(lm(~~~),direction='both') |
상관분석
상관 계수? 두 변수의 관련성의 정도를 의미(-1 ~ 1)
두 변수의 상관관계가 존재하지 않을 경우 상관계수는 '0' 이다.
상관관계가 높다고 인과관계가 있지는 않다.
피어슨 상관계수와 스피어만 상관계수가 있다.
| 피어슨 | 스피어만 | |
| 개념 | 등간척도,비율척도 간의 선형적인 크기 측정 | 서열척도의 비선형적인 관계 측정 |
| 특징 | 연속형변수, 정규성 가정 | 순서형변수, 비모수적 방법 |
| 상관계수 | 피어슨 r(적률상관계수) | 순위상관계수 로우 |
| R코드 | cor(x, y, method=c("pearson","kendall","spearman")) | |
차원 축소 기법
주성분 분석(PCA, Principal Component Analysis)
데이터 분석을 할때 변수의 개수가 많다고 무조건 좋은건 아니다(다중공선성의 위험성)
공분산행렬 또는 상관계수 행렬을 사용해 모든 변수들을 가장 잘 설명하는 주성분을 찾는 방법
상관
관계가 있는 변수들을 선형 결합에 의해 상관관계가 없는 새로운 변수를 만들고 분산을 극대화하는 변수로 축약
독립 변수들과 주성분과의 거리인 "정보손실량"을 최소화 하거나 분산을 최대화한다.
공분산 행렬 vs 상관계수 행렬
공분산 행렬은 변수의 측정단위를 그대로 반영, 상관계수 행렬은 모든 변수의 측정단위를 표준화
설문조사 처럼 모든 변수들이 같은 수준으로 점수화 된 경우 공분산행렬을 사용한다.
변수들의 scale이 서로 많이 다른 경우에는 상관계수행렬을 사용한다.
| 주성분 분석에서 상관계수 행렬 사용 | prcomp(data, scale = TRUE) princomp(data, cor = TRUE) |
성분들이 설명하는 분산의 비율
누적 분산 비율을 확인 하면 주성분들이 설명하는 전체 분산 양을 알 수 있다.

고윳값
분산의 크기를 나타내며, Scree Plot은 고윳값을 가장 큰 값에서 가장 작은 값 순서로 정렬해서 보여준다.

주성분의 로딩벡터 나타내기
사용법 : fit$rotation

주성분 분석 해석하기
Standard deviation(표준편차) : 자료의 산포도를 나타내는 수치로, 분산의 양의 제곱근, 표준편차가 작을수록 평균값에서 변량들의 거리가 가깝다
Porportion of Variance(분산비율) : 각 분산이 전체 분산에서 차지하는 비중
Cumulative Proportion(누적비율) : 분산의 누적비율

시계열 예측
시계열 분석을 위해서는 정상성을 만족해야 한다.
정상성(stationary)? 시계열의 수준과 분산에 체계적인 변화가 없고, 주기적 변동이 없다는 것
미래는 확률적으로 과거와 동일하다!
정상 시계열의 조건 : 정상성을 가지고 있는 시계열의 조건
1) 평균은 모든 시점에 대해 일정하다
2) 분산은 모든 시점에 대해 일정하다
3) 공분산은 시점에 의존하지 않고, 단지 시차에만 의존한다.
정상 시계열로 전환하는 방법 : 차분, 변환
차분 : 현 시점의 자료 값에서 전 시점의 자료 값을 빼주는 것 > 평균이 일정하지 않을때 사용
변환 : 분산이 일정하지 않을 때 사용
분해시계열
시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
| 추세요인 | 자료에 그림을 그렸을 때 그 형대타 오르거나 내리는 등 어떤 특정한 형태를 취할 때 |
| 계절요인 | 계절에 따라, 고정된 주기에 따라 자료가 변화하는 경우 |
| 순환요인 | 급격한 인구 증가 등 알려지지 않은 주기를 가지고 자료가 변화하는 경우(주기가 있음) |
| 불규칙요인 | 추세,계절,순환으로 설명할 수 없는 오차에 해당하는 요인 |
References
2021 ADsP 데이터 분석 준전문가, 윤종식 저
https://www.youtube.com/c/EduAtoZPython/videos
EduAtoZ - Programming
An extreme programming education channel
www.youtube.com
'Data analysis > ADsP' 카테고리의 다른 글
| [ADsP][3과목] 5장. 정형 데이터 마이닝 (0) | 2021.08.21 |
|---|---|
| [ADsP][3과목] 4장. 통계분석의 이해 (0) | 2021.08.21 |
| [ADsP][3과목] 3장. 데이터 마트 (0) | 2021.08.20 |
| [ADsP][3과목] 1,2장. 데이터 분석 개요, R프로그래밍 기초 (0) | 2021.08.20 |
| [ADsP][2과목] 2장. 분석 마스터 플랜 (0) | 2021.08.20 |